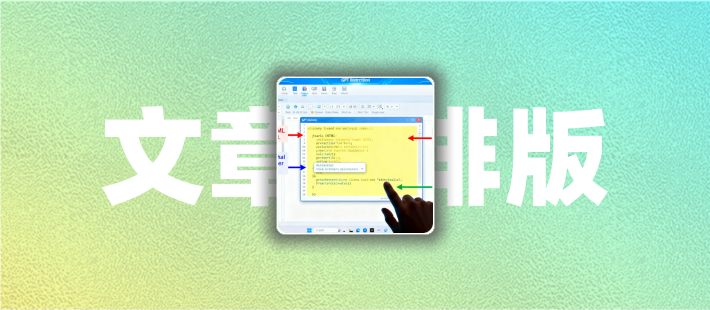
Robots.txt防止网站内容误删

Robots.txt防止网站内容误删
Lifeline一、引言

网站管理员常因robots.txt配置不当导致重要页面被搜索引擎误删,造成流量严重损失。错误的屏蔽指令会让爬虫无法索引关键内容,从而影响整体SEO表现。精准配置robots.txt是避免内容误删的首要防线。
robots.txt文件虽小,却直接控制搜索引擎爬虫的抓取权限。一旦规则设置错误,可能数月难以恢复排名。定期审计robots.txt规则应成为网站维护的常规操作,从而持续保障内容可见性。
二、哪些常见错误会导致网站内容被误屏蔽?
错误配置robots.txt是内容被误删的主要根源,其中路径大小写错误和通配符滥用最为常见。部分管理员会意外屏蔽整站资源,导致CSS/JS文件无法被抓取。错误使用Disallow: /会直接让整个网站从搜索结果中消失,这是最致命的操作失误。
- 错误路径大小写:服务器区分大小写,/Admin/和/admin/是不同的路径
- 过度使用通配符:不当使用
*和$可能导致规则覆盖范围超出预期 - 屏蔽关键资源:阻止爬虫访问CSS/JS文件会影响页面渲染和理解
- 错误位置放置:文件未放置在根目录将完全失效
🔍 避免这些错误是防止内容误删的基础
三、如何测试robots.txt规则避免误删?

测试是确保robots.txt规则正确性的关键环节。Google Search Console提供了官方测试工具,可以模拟爬虫行为。在GSC中测试每条规则能提前发现潜在误屏蔽问题,避免实际上线后造成损失。定期使用第三方工具进行全面爬取模拟也很必要。
- Google Search Console测试工具:谷歌官方工具,可逐条验证规则效果
- 爬虫模拟测试:使用Screaming Frog等工具模拟搜索引擎爬虫行为
- 生产环境验证:直接访问yoursite.com/robots.txt确认最终效果
- 定期回归测试:网站改版后重新测试所有规则
✅ 全面测试是防止误删的最可靠保障
四、规则冲突时如何确定优先级?

当Allow和Disallow规则出现冲突时,搜索引擎会按照特定优先级处理。最具体的规则通常优先级最高,这与CSS的优先级计算方式类似。理解这些优先级规则对于编写准确的robots.txt文件至关重要。
- 具体规则优先:/page/比/*更具体,优先级更高
- 顺序无关原则:优先级不由规则出现顺序决定
- 字符长度判断:路径更长的规则通常更具体
- Google官方优先级说明:谷歌采用最长匹配原则
⚖️ 理解优先级规则是编写准确指令的前提
五、常见规则错误与正确写法对比
六、拓展防护策略
除了正确配置robots.txt外,还应采用多层次防护策略防止内容误删。结合使用meta robots标签可以提供双重保障,即使robots.txt出现问题也能减少损失。以下策略按实施优先级排序:
- Meta Robots标签补充:在重要页面使用
<meta name="robots" content="index">强化指令 - Search Console监控:定期检查覆盖率报告,及时发现索引问题
- 日志文件分析:监控爬虫实际访问行为,验证规则有效性
- 权限层级检查:确保测试环境与生产环境的robots.txt一致性
七、结论
robots.txt管理需要系统性的方法和持续的关注。建立robots.txt的定期审计机制是避免内容误删的最有效方法。通过结合工具测试、优先级理解和多层防护,可以最大限度降低误屏蔽风险。保持配置的最小化和精确化是现代网站SEO最佳实践的核心组成部分。